
Service 服务项目 
如何提高Redis的持久性?
 返回列表
返回列表
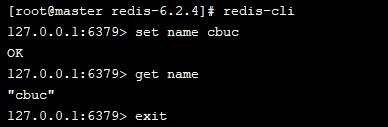
` 是否仍然存在。如果能够看到我们的数据,这表示 Redis 持久化操作成功了。然后我们删除了刚刚生成的 dump-test.rdb 文件,并重新启动 Redis。这表明 Redis 在启动时依赖 .rdb 文件来恢复数据。接下来,我们需要删除刚生成的dump-test.rdb文件,并重新启动Redis
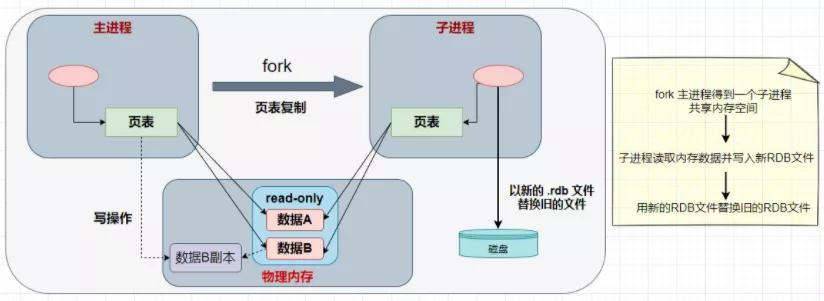
。这说明Redis启动时依赖.rdb文件来恢复数据。那么,我们之前提到的bgsave是如何执行的呢?我们之前提到了两个概念fork和cow,不知道大家是否还记得。这两个概念非常重要!发起bgsave命令时,主进程将会复制出一个新的子进程,而这个子进程将会与主进程共享内存数据。子进程会把数据写入一个临时的 .rdb 文件,当子进程写完临时文件后,会用它来替换原来的 .rdb 文件。这个是 fork 的核心原理,那么什么是 cow 呢?cow技术的全称是写时复制技术。当主进程进行读操作时,它会访问共享内存,而执行写操作时,它会复制一份数据并进行写操作。
的具体流程如下:
那么,这种持久化方式有哪些优点呢?数据持久化方式 RDB 具有一些优势:
方便持久化,只需一个 dump.rdb 文件
具备容灾性,可将文件保存到安全的磁盘中
最大化性能,通过 fork 子进程完成写操作,使主进程继续处理命令,最大限度地提高 IO,确保 Redis 高性能
不过,RDB 也存在缺点:
数据安全性低,RDB 定期持久化(save),若 Redis 在持久化期间发生故障,可能导致数据丢失,因此适用于数据要求不是非常严格的情况
长时间保存,对于大数据量,快照保存时间较长,会占用磁盘空间
因此, RDB 数据持久化方式有其优劣之处。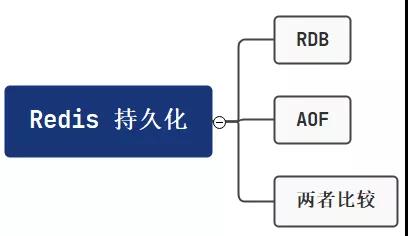 二、AOF
二、AOF
如果了解 Mysql 中relay log 日志的同学,对于这种模型,您一定会感到非常熟悉。
的工作原理是将写入命令追加到AOF文件的末尾。为了使用AOF持久化功能,需要设置同步选项,以确保写入命令在合适的时机被同步到磁盘文件上。这是因为写入文件时,并不会立即将内存内容同步到磁盘文件上。相反,写入操作会先存储在缓存区中,然后由操作系统决定何时将其同步到磁盘。
的原理是将写入命令追加到AOF文件的末尾。使用AOF持久化需要设置同步选项,以确保写入命令同步到磁盘文件的时机。这是因为对文件进行写入并不会立即将内存同步到磁盘上,而是先存储到缓存区,然后由操作系统决定何时同步到磁盘。
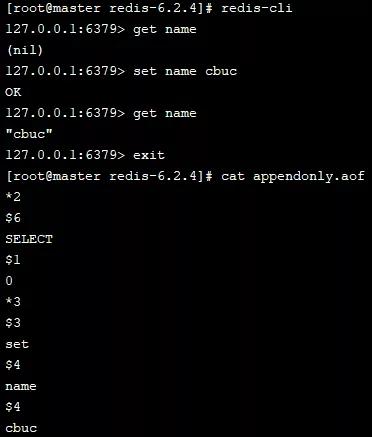
我们打开AOF记录功能来查看:
 可以看出每次操作均已记录到AOF文件中。即使重新启动Redis,也可以获取刚才存储的数据,证明持久化已生效。
可以看出每次操作均已记录到AOF文件中。即使重新启动Redis,也可以获取刚才存储的数据,证明持久化已生效。
看到上面的AOF记录文件,感觉整齐规范吗?但是在在线环境中过于规整反而不利,因为这些文件主要是供机器阅读,而不是人类阅读。因此最好能够进行压缩处理。
 为了解决AOF文件体积不断增大的问题,用户可以向Redis发送 bgrewriteaof命令,这个命令会通过 通过移除AOF文件中的冗余命令 来重写(rewrite)AOF文件,使AOF文件的体积变得尽可能地小。bgrewriteaof的工作原理和 bgsave 创建快照的工作原理非常相似:Redis会创建一个子进程,然后由子进程负责对AOF文件进行重写。因为AOF文件重写也需要用到子进程,所以快照持久化因为创建子进程而导致的性能问题和内存占用问题,在AOF持久化中也同样存在。既然我们可以手动触发压缩,那么也可以自动触发压缩。这就需要提到两个配置项在配置文件中:auto-aof-rewrite-percentage和auto-aof-rewrite-min-size。这些配置项的含义是,当AOF文件的大小超过64MB,并且比上一次压缩后的大小至少增加了一倍(100%)时,Redis将执行bgrewriteaof命令。总结一下,它的优点如下:\n1. 数据安全。AOF持久化可以设置appendfsync属性为always,每执行一次写命令操作都会立即将其记录到AOF文件中,以确保一致性。通过使用 append 模型来进行文件写入,即使服务器在中途宕机,也可使用 redis-check-aof 工具解决数据一致性问题。
为了解决AOF文件体积不断增大的问题,用户可以向Redis发送 bgrewriteaof命令,这个命令会通过 通过移除AOF文件中的冗余命令 来重写(rewrite)AOF文件,使AOF文件的体积变得尽可能地小。bgrewriteaof的工作原理和 bgsave 创建快照的工作原理非常相似:Redis会创建一个子进程,然后由子进程负责对AOF文件进行重写。因为AOF文件重写也需要用到子进程,所以快照持久化因为创建子进程而导致的性能问题和内存占用问题,在AOF持久化中也同样存在。既然我们可以手动触发压缩,那么也可以自动触发压缩。这就需要提到两个配置项在配置文件中:auto-aof-rewrite-percentage和auto-aof-rewrite-min-size。这些配置项的含义是,当AOF文件的大小超过64MB,并且比上一次压缩后的大小至少增加了一倍(100%)时,Redis将执行bgrewriteaof命令。总结一下,它的优点如下:\n1. 数据安全。AOF持久化可以设置appendfsync属性为always,每执行一次写命令操作都会立即将其记录到AOF文件中,以确保一致性。通过使用 append 模型来进行文件写入,即使服务器在中途宕机,也可使用 redis-check-aof 工具解决数据一致性问题。
\n AOF 文件较 RDB 文件大,恢复速度慢 \n 数据集较大时比 RDB 文件的启动效率低
\n在优缺点均沾的情况下,需要谨慎选择\n另外,我们来介绍一下两种文件的区别\n分别介绍这两者后,我们来回顾一下它们之间的区别。
, 方面的 RDB AOF , 持久化方式中的定时对整个内存做快照每次执行的命令都会被记录 数据的完整性 在两次备份之间可能会有数据丢失 相对而言更为完整。 刷盘策略的选择取决于多个因素。例如,文件大小和压缩对文件体积的影响,以及记录命令对文件体积的影响。此外,宕机恢复速度也是考虑因素,它可能快速或慢速。数据恢复的优先级也很重要,像AOF因数据完整性较高,因此优先级较高,而其他可能会较低。由于数据的完整性更高,系统所占用的资源会更多,其中大量的CPU和内存消耗较少,主要消耗的是磁盘IO资源。且 AOF 重写时会占用大量CPU和内存资源 使用场景 可以容忍数分钟的数据丢失,追求更快的启动速度 对数据安全性要求较高
看完上面后,想必对两种持久化机制都有一定的了解了。且 AOF 重写时会占用大量CPU和内存资源 使用场景 可以容忍数分钟的数据丢失,追求更快的启动速度 对数据安全性要求较高看完上面后,想必对两种持久化机制都有一定的了解了。两者都有优劣势,那我们该如何选择?以下是几点建议:如果您可以容忍短时间内的数据丢失,可以采用 RDB 机制,定时生成 RDB 快照。此外,相比于 AOF,使用 RDB 恢复数据集的速度更快。但是,仅仅使用 RDB 机制可能会导致很多数据丢失,因此我们需要综合使用 AOF 和 RDB 两种持久化机制来确保数据的安全性。我们可以使用 AOF 作为数据恢复的第一选择,保证数据不丢失;同时,使用 RDB 做不同程度的冷备份,在 AOF 文件都丢失或损坏不可用的情况下,可以使用 RDB 进行快速的数据恢复。总之,充分利用 RDB 和 AOF,可以快速恢复数据。通过配置 AOF,可以完善数据
的持久化。本文已经讲述了 Redis 持久化机制的配置。相信通过学习本文,面试时遇到有关此问题,也会游刃有余!不要光说不做,不要懒惰贪图安逸,一起来和小编成为自夸技术的程序员吧~点个关注,一起相伴,让小编不再孤独。




 友情链接:
友情链接:




